How We Accurately Tagged 38.000 Flemish Private Swimming Pools
Using open aerial images, a list of 1000 addresses with swimming pools, and gdal, aws and scikit-learn as data science tools.

At Rockestate, we are always looking for methods to derive properties for every single house in Belgium. These properties, or features as they’re commonly called in data science, allow us to predict a price of every house in Belgium. Features such as “is there a swimming pool in the garden of the house” also allow us to build mortgage pricinge, insurance risk or energy consumption models for banks, insurers, energy providers and telcos.
In this blogpost we describe our methodology to predict for each house in Flanders the presence of a swimming pool.
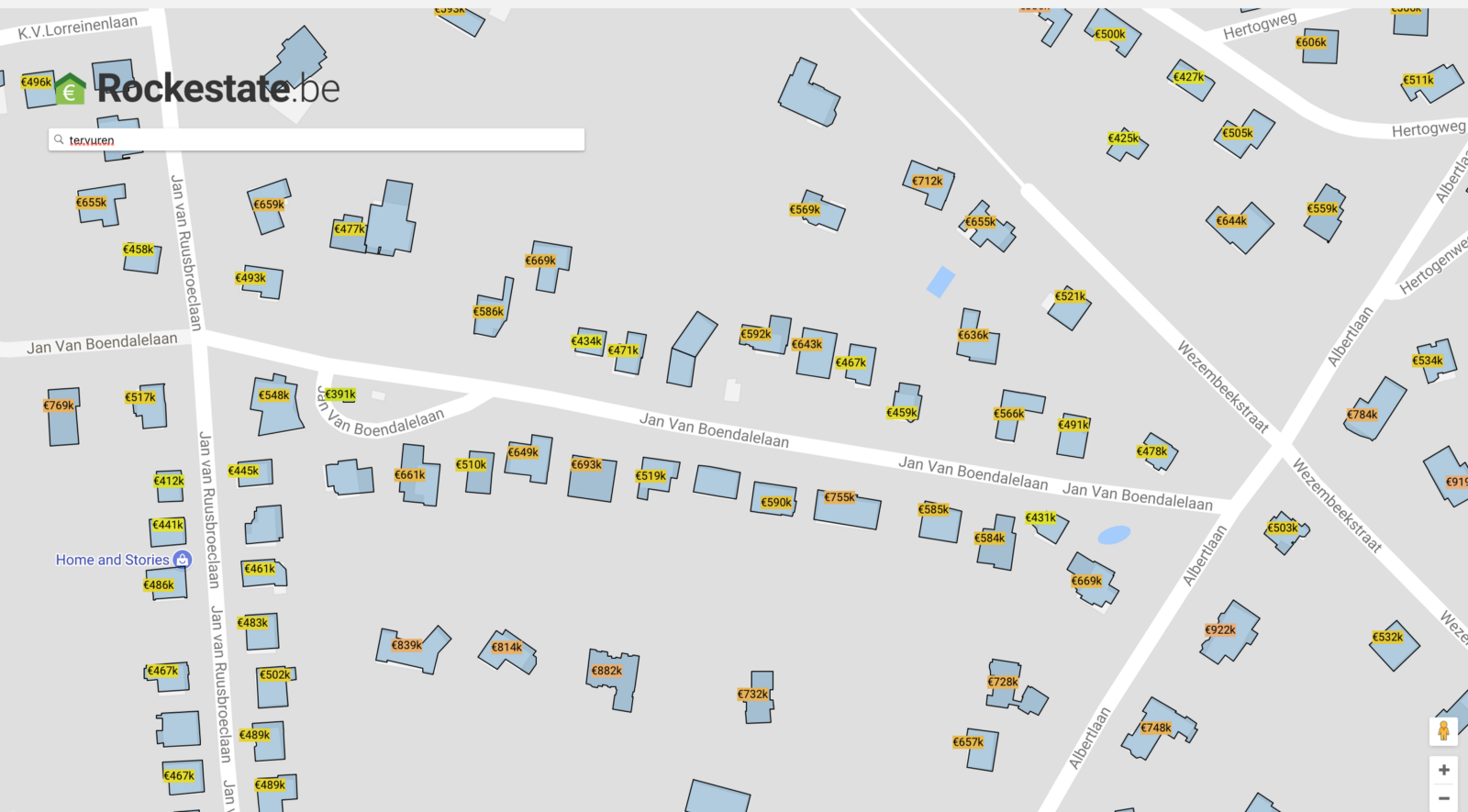
Feature engineering out of open data is hard work. Such open sources include cadastral files (geospatial shape files) or aggregated neighborhoud census statistics. Using these, we have already calculated many features, such as the distance of a house to the street or the number of attached neighbors for every house in Belgium.
In this blog post, we want to focus on another form of data which allows to derive useful information regarding real estate properties: aerial images. Contrary to census data, which is highly structured and geospatial shape data, which is still somewhat structured by means of geometric primitives (polygons and other shapes), aerial images are an example of a highly unstructured form of data and thus comes with several challenges to embed such data in analytical models.
In recent years, we have seen the rise of deep learning based techniques (such as convolutional neural networks) to tackle such high- dimensional, unstructured data, but since this was our first time working with this data set, we wanted to see whether we could already extract useful information using the analytics pipeline we were already accustomed to.
The first task we had in mind was to find every house with a swimming pool. Shouldn’t be too hard right?
Quick intro to machine learning.
Our ultimate goal for this task is to construct a predictive model. This model will be trained based on a well-prepared data set to recognize a swimming pool.
The features the predictive model will use are:
-
Properties of the building itself, such as the house type (e.g. a villa is more likely to have a swimming pool compared to an attached househouse, so that this is useful information to our predictive model). We already have built up a variety of such properties in our repositories.
-
An aerial image of the garden, i.e. the new form of data we’ll be using. It is likely that a well-performing model will be able to derive most information from this feature, as an image with a big blue spot in it, is likely to have a swimming pool.
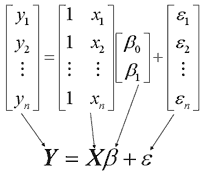
In very short, we look for a function using a feature matrix X, predicting the variable y which is in this case indicates the presence of a swimming pool (y is binary). In the formula below, all entries in Y are hence either zero or one, and X contains the features of each building.
The goal of predictive analytics is then to construct a good relation between y and X, or to learn the probability that a house has a swimming pool given a feature set for the property. Several techniques have been devised to learn such a relationship. In the the previous simple formula, a linear model is shown, which simple multiplies X with a feature effect vector beta. The training of such a model then consists of learning the “best” entries of beta.
Overview of steps
The following describes our (current) final solution. Looking back, we see a lot of ways to expand upon our first try-out, though we still managed to produce an accurate model to detecting swimming pools using mostly open data.
This is what we have done:
- Obtain accurate (infrared) aerial images
- Obtain a list of known swimming pools
- Clipping the infrared images based on the contours of the parcels
- Extracting features out of the clips
- Constructing the predictive model
- Validation of the model on unseen properties
Obtaining accurate (infrared) aerial images
Getting access to well-curated open data sets in Belgium can be very challenging. To provide some background: In our tiny little country, there are three regions, all with their own governments, institutions, policies and budgets. Flanders is only one region of Belgium, but tends to provide open data of high quality. One of such data are the (infrared) aerial images, provided by Geopunt. Below you see a screenshot of the aerial imagery for the whole of Flanders.

The resolution provided is high, with one pixel covering a 40cm square area. Both infrared and the normal (RGB) images are available, including the region of Brussels (which is technically another region).
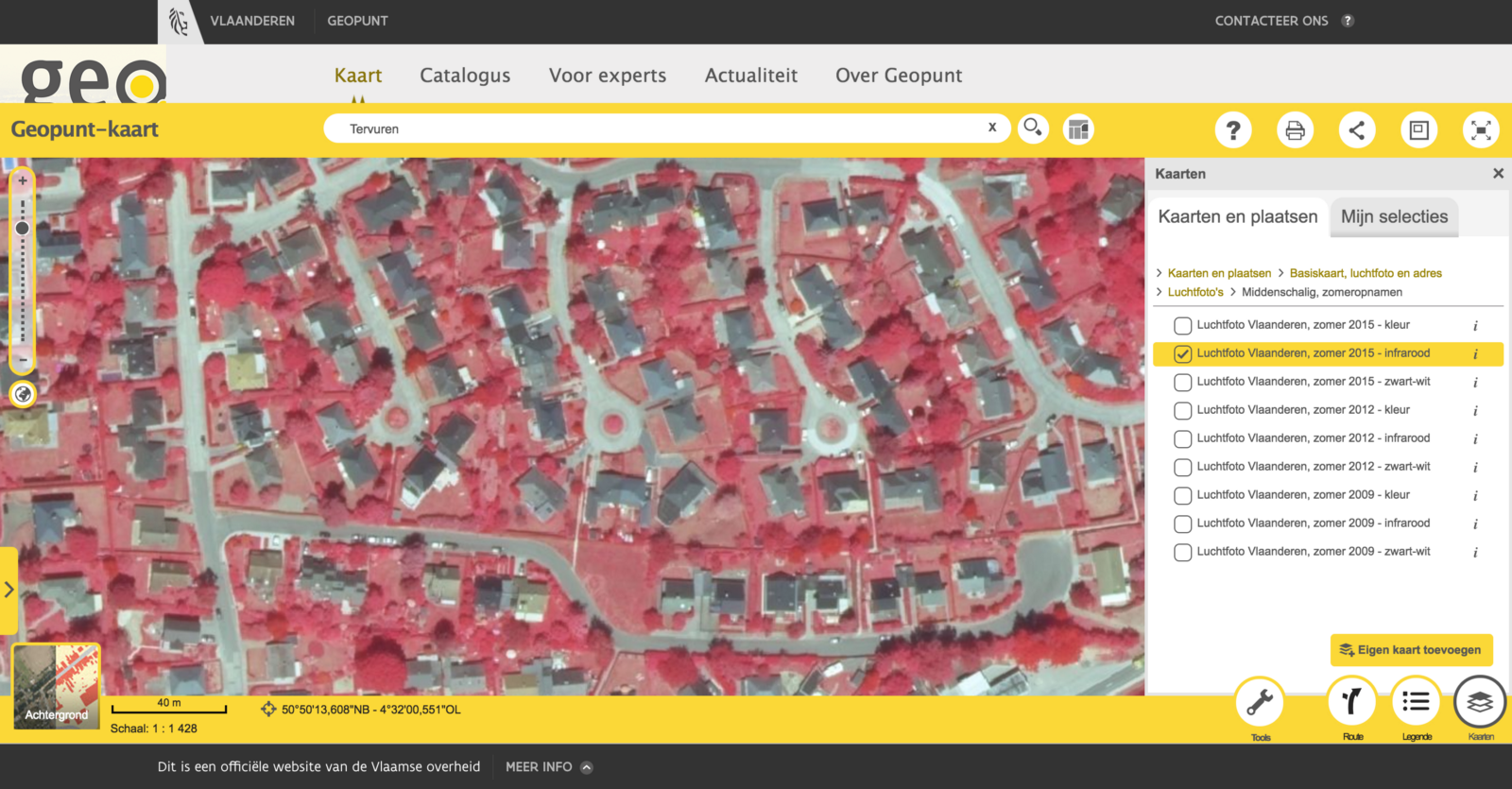
Due to the high resolution however, this data is quite cumbersome to work with. The data set is provided as 43 images of weighing 600Mb each (compressed using JPEG 2000). A lot of time was spend in preprocessing these into a more manageable format.
Obtaining a list of known swimming pools
There is another issue we had to resolve to construct our predictive model. Most of predictive techniques utilize “supervised learning”, which means that — in order to train the model — you need to provide a feature matrix X as well as a list of known outcomes Y. This means that we need at least some examples of properties containing swimming pools, and examples of properties that do not.
Naturally, we could have manually gone through a number of properties in order to label them, though this is a very time-consuming task and not something we were very eager to do. Luckily, someone had been tagging private swimming pools in Flanders around the town Merchtem on OpenStreetMap. Using an OSM query we were able to identify 180 swimming pools.
However we still wanted more, and contacted a Belgian real estate web portal to export some real estate advertisements for which the owner had indicated the presence of the pool. This export provided us with 5.000 addresses with a swimming pool, largely sufficient to train our supervised model.
Clipping the infrared images with the contours of the parcels
There are 2 million of buildings in Flanders that are eligible to have a swimming pool. for each of these, we wanted to extract the associated infrared image. To do so, we use the GDAL toolkit which provides a function to do exactly this. (http://www.gdal.org/gdalwarp.html)
Clipping 2 million parcels is a cumbersome task. We wanted to cut the house out of the images as well, making the clipping task even more challenging. The keep computation time manageable, we set up a heavy AWS instance which was able to clip all 2 million buildings in 24 hours.

Extracting features out of the clips
Most predictive techniques still require a feature matrix X to be represented as… well, a matrix. This means that we have to convert to infrared images to a series of feature, i.e. column in the feature matrix X.
Many different ways exist to do so. For instance, one way is to create three columns (one for each color channel) per pixel in the image. However, this will lead to an explosion of features, which most supervised techniques are not able to handle. Instead, we opted for the following approach:
- Calculate for each image the histogram of each color channel (three per image)
- Divide this histogram into 50 bins
- Count the number of pixels in each bin
Each image is hence converted into 150 features, combined with general building features such as building type, distance to street etc.
Lets take the features of the a building as an example. This house has the following distribution of pixels over the color bands. The resulting features are also plotted on the histogram (the zeros are left out).
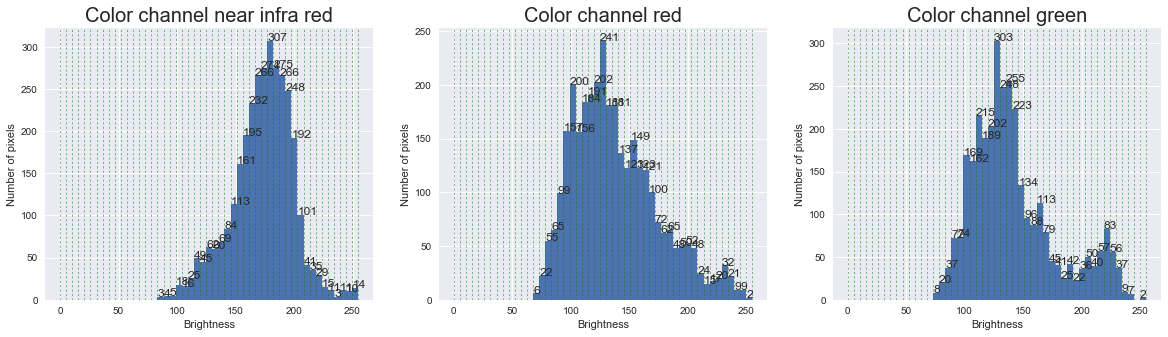
Update: we ended up calculated features a bit different, by transforming the pixels to the HSV space and applying a blue filter.

Training the predictive model
Why do we need a machine learning model?
You might think that it should be possible just to write a “rule” or heuristic that checks if there are some blue pixels in the image. However, fine tuning such rules manually (setting the thresholds for instance) is a cumbersome task. A predictive model is a lot bettering in finding the most efficient rule (or combination of rules).
Training a random forest
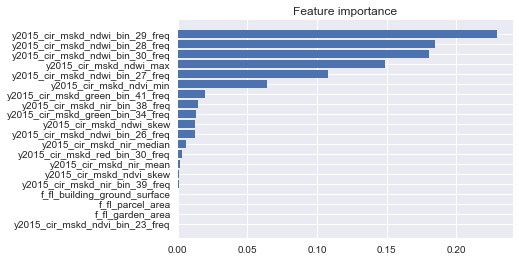
We opted to use the Random Forest technique as provided by sklearn. Random Forests are a flexible, easy to use predictive technique which constructs a collection of decision trees: a collection of rules to identify a particular target. Another benefit of this technique is that is can provide a feature importance ranking, indicating which features “helped most” to predict our given target:
Validation of the model
After training a supervised model, it needs to be validated against a labeled data set which was not used during training in order to get an idea how well the model has learned to predict the target (and also: the verify whether the model has not just “memorized” the given training data).
Several metrics exist to quantify a model’s predictive power. We ended up comparing recall recall versus discovery discovery rate.
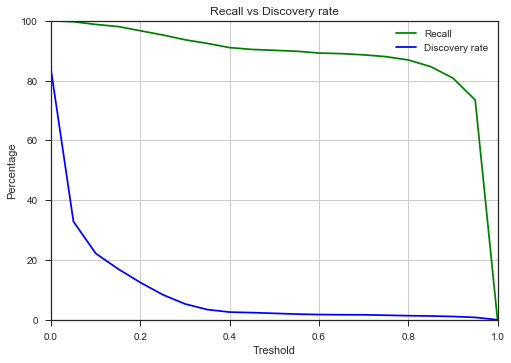
Recall represents the percentage of labeled pools we correctly predict. Since there were still a lot of properties in our data set for which we had no known label, we also verified the percentage of unlabeled properties predicted having a swimming pool, shown here as the discovery rate. As you can see on the graph, our model works well: if we use a probability threshold of 0.5, we are able to correctly capture 90% of the labeled swimming pools, with a new discovery rate of around 1.5%. This means that 1.5% of all buildings in Belgium eligible to have a swimming pool seem to have one, which seemed ok to us.
Results
And here we are, using this Random Forest model we can predict all properties of Flanders. Out of the 2 million clips, our model identiefied around 38.000 swimming pools. Check a subset of them out on this Carto app!