Discovering structure in first names by analysing user clicks
Thousands of people clicked on hundreds of names on our recommender system NamesILike.com. The result of applying matrix factorization on these user clicks reveal an unseen structure in our first names.
It’s no secret that one of our hobby projects is the first name recommender system NamesILike.com. This website recommends first names to the user, after asking 20 questions to find out their taste. It is mostly used by future parents who are in the process to pick a name for their expected child. Recommender systems such as this one are hot in the data-science field! Famous examples are the recommender systems of Spotify, Netflix, Pandora, Last.fm and YouTube.
One of the challenges of recommender systems is to pick up the taste of the user as fast as possible. Users generally have a short attention span when surfing the web and expect to see results fast. We decided to learn about the user’s taste by asking 20 multiple choice questions. Each question lists 4 names, out of which the user can indicate their favorite (without thinking about it too much). The screenshot below provides an example:
In December 2017, Names I Like received around 40.000 visitors thanks to a viral effect. The clicks of all these users generated a nice dataset, as we keep track of the series of questions presented to each user as well as the option that was chosen. After some data manipulation, we can hence construct a user-feedback table with columns “q” for question number, “f” for feedback, and “n” for name. The feedback is either “c”, which stands for clicked, or “nc” which stands for not-clicked. This table we call a user-feedback table. The table below shows the first 10 lines of a user-feedback table for a random user:
| f | n | q | |
|---|---|---|---|
| 0 | nc | Lia | 1 |
| 1 | c | Bo | 1 |
| 2 | nc | Heleen | 1 |
| 3 | nc | Zehra | 1 |
| 4 | nc | Lou | 2 |
| 5 | nc | Lise | 2 |
| 6 | nc | Laurence | 2 |
| 7 | c | Annelies | 2 |
| 8 | nc | June | 3 |
| 9 | c | Liv | 3 |
The user-item matrix, also known as the utility matrix, is derived by concatenating all the user-feedback tables. Items are first names in our case (for Netflix items are movies and for Spotify items are songs). The value in each cell_ij tells us whether the user_i clicked on the product_j. We encoded a click on a name with a value of 3, and a non-click with a value of -1, so that way the sum of the feedback for one user is zero. The table below shows a fragment of the user-item matrix.
| name | Amelia | Clara | Elise | Emma | Lilly | Linde | Lise | Lou |
|---|---|---|---|---|---|---|---|---|
| user_id | ||||||||
| 0044dDn5Mh1V0O9Pwa8c | 3.0 | -1.0 | -1.0 | NaN | -1.0 | -1.0 | -1.0 | NaN |
| 00JcVTsDJ6wqJp4ymt40 | NaN | -1.0 | NaN | 3.0 | -1.0 | NaN | 3.0 | 3.0 |
| 00XJDcHhXwgAs64zRsZE | -1.0 | -1.0 | NaN | NaN | 3.0 | -1.0 | 3.0 | NaN |
| 010BLu21DwkpbZSVppZp | -1.0 | -1.0 | -1.0 | -1.0 | 3.0 | NaN | 3.0 | 3.0 |
| 01HiqB25APOJYRNgoEod | NaN | -1.0 | -1.0 | NaN | -1.0 | 3.0 | -1.0 | -1.0 |
| 01Ib76OTt49y3wUH0feO | NaN | NaN | -1.0 | -1.0 | NaN | NaN | NaN | 3.0 |
| 01MGzUmLfh4opU5FC6xd | 3.0 | -1.0 | NaN | -1.0 | NaN | -1.0 | NaN | -1.0 |
| 01hL2EYynEQA9CQBckSM | 3.0 | NaN | 3.0 | -1.0 | -1.0 | -1.0 | NaN | NaN |
| 0294V1C2QYgQ35tFkJkF | -1.0 | NaN | 3.0 | -1.0 | -1.0 | -1.0 | -1.0 | NaN |
| 02jmn1zx5aJ3oJBdx1Qb | -1.0 | NaN | 3.0 | NaN | NaN | NaN | 3.0 | 3.0 |
This table has of course a lot of missing values (NaN), as not every user saw every name. The art of recommender algorithms is to complete this matrix by predicting the missing values. These predictions represent the feedback that we expect a user to give for an item which was not seen so far. We can then simply rank these predictions, and recommend the item (first name) with the highest prediction.
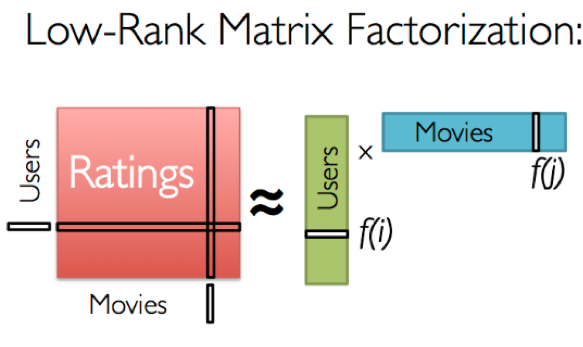
There are many ways of completing this matrix, but we focus here on completing the matrix with a latent factor model. Explaining the details of this method goes too far for this blog post, but we encourage you to watch this excellent Stanford tutorial. In short, the goal of the latent factor model is to estimate the user-item matrix through a product of two (smaller) matrixes, the first of which has the same number of rows as users, and a number of columns representing “latent features”. The second matrix has the same number of columns as there are items, and the latent features now encoded over the rows. A perfect estimate of the original user-item matrix is impossible through this decomposition, but we try to construct the two matrixes so that their product comes as close as possible to the original. Their latent features then encode a decomposed, compact representation of the original information.
What are these latent features (or hidden characteristics)? What do they represent? That is hard to say as they are chosen through an optimization process. Recall that the latent features are constructed in such a way such that the product of the latent feature matrices is as close as possible to the complete matrix. Or in other words, the latent features are chosen in such a way that the information loss going from the complete user-item matrix to approximation with two smaller latent feature matrices is as small as possible. The graph below visualizes the values of the first two latent features for each female first name item:
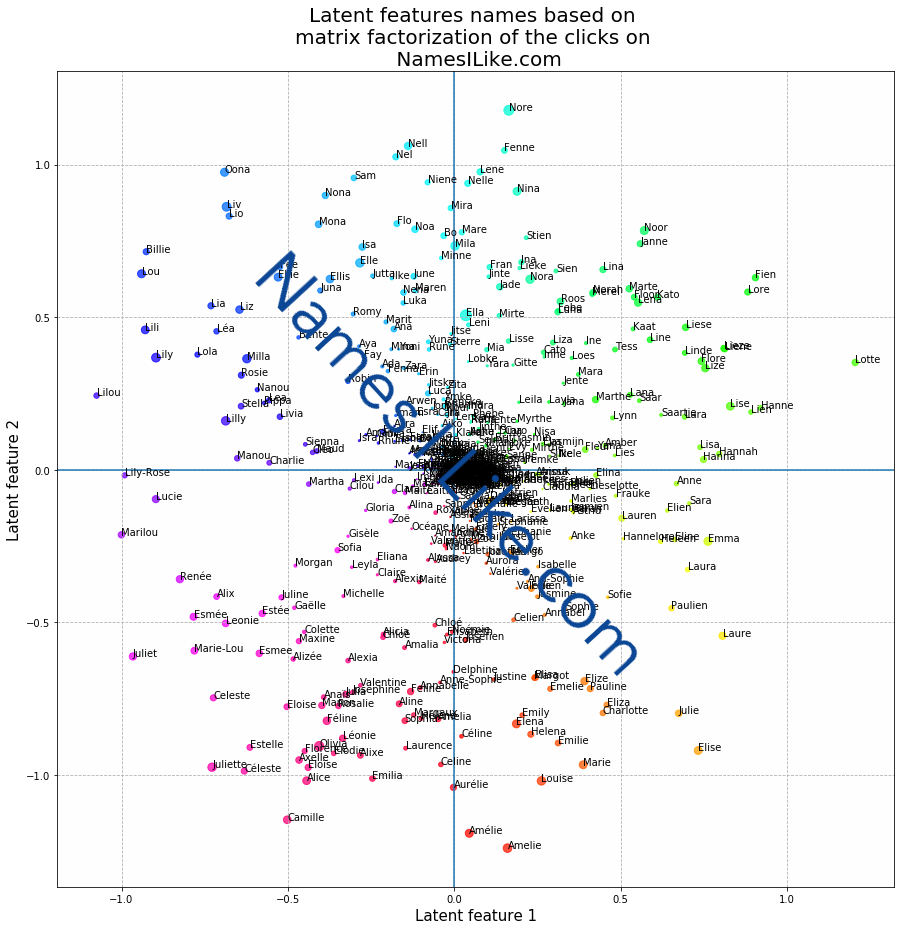
By visually inspecting this graph, we do observe that “similar” names are positioned close to each other in this new latent feature space:
- French names, such as (Camille, Alic, Amelie) seem to have low values for latent feature 2;
- Very Flemish names (Fien, Fenne, Nore, Janne) seem to have high values for latent feature 2 and high values for latent feaure 1;
- Short names (Lia, Liz, Lou) seem to have low values for latent feature 1 and high values for latent features 2.
We believe this is magical. Although for us humans it is logical that the name Juliette is close to Estelle and Celeste, it seems odd that an algorithm can understand this subjective taste. But this is exactly what happend : the algorithm understood the subjective taste present in the original ratings of all our users, and was able to extract similarities between first names purely based on the clicks of users on our website.
These latent features help us to do two things: improve the accuracy of the predictions and setting up a sampling scheme for the multiple-choice questions. More on that in a later blog post.