Old school feature engineering
Although automated feature engineering is hot today, we still highly value feature engineering based on background knowlegde. We demonstrate this approach with an example.
These days data is often abundant, which makes it possible to automate feature engineering. That is often a good approach, but we like still like the classical way of feature engineering, being building a feature based on background knowledge. You start with an idea based on the real world knowledge you have about the problem, you implement the feature and you test the performance in your model.
Let’s give a concrete example of this approach. In our statistical model we use the number of bedrooms to predict the price of an apartment. But there is a special kind of apartment, which is a studio. It is an apartment with zero bedrooms: the main room is basically the kitchen, living room and bedroom. Would it help to take into account that the apartment is a studio? Or doesn’t it add extra information compared to an apartment with one bedroom? And if we believe the feature adds information, do we encode it as a boolean or as a numerical value?

Example of a studio, which is an apartment with just one large room.
Out of our data we had some ways to figure out if a real estate listing is a studio. There is a property which says so, but it is rarely filled in. And we searched it in the text description.
Now that calculated the feature, we would like to make some plots to see if the feature makes sense. First, we expect that studios have a smaller livable area compared to apartments with separated bedrooms. We could check this with a boxplot. What we don’t like however about standard boxplots is that each boxplot has the same width. We want to get a feeling how much data there is in each box. Instead of boxes for each category, we just plot the x-value with some noise, aka a strip plot (altenative approaches include violin plots and swarm plots).
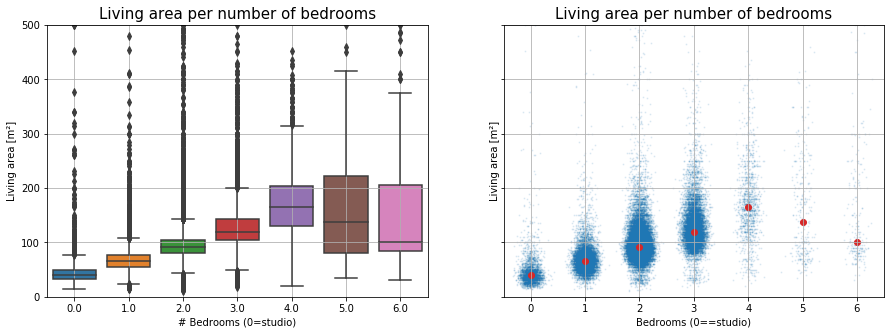
Boxplot versus a scatter plot with noise. Don't you think the boxplot puts too much attention on the 6 bedroom apartments, although there are very few of them?
From this graph, we can already take some conclusions:
- Most of the apartments have three or fewer bedrooms. There seems to be data issues for the few apartments with five or more bedrooms, so we’ll ignore those going forward.
- The living area of a studio seems to be smaller than the living area of apartments with proper bedrooms.
So our feature studio seems to be calculated correctly. Does it say something about the price of an apartment? Let’s make the same plot but with the price on the y-axis. And as you might now, the distribution of the price of a real estate is skewed to the left, so lets also make a plot with the logarithm of the price on the y-axis.
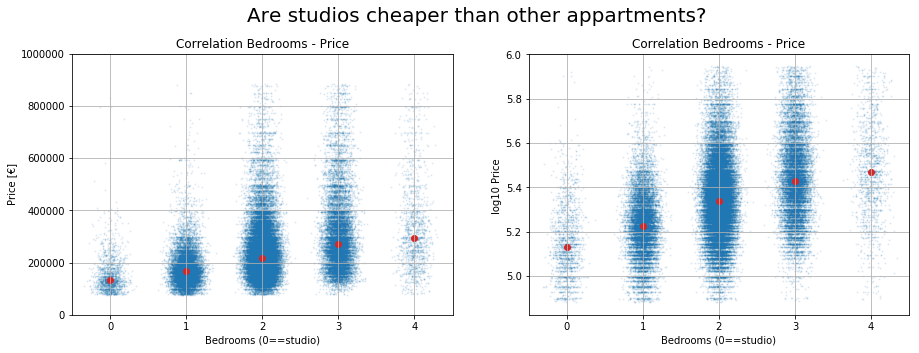
This graph seems to confirm our idea: making the distinction between one bedroom apartments and studios will increase the power of our predictive models. If we set the number of bedrooms to zero, the relation between bedrooms and log-price even seems to be linear. The details of the effect of on the prediction power of our model will be for another blogpost.
The last graph reveals however that we have taken a too rough lower cut on the price. We will need to fix that asap. Finding this mistake with solid plots makes our argument of not ignorning the classic feature engineering even stronger…