Comment le Zimmo Prijswijzer aide-t-il à estimer le prix d'une maison?
Zimmo a lancé, en collaboration avec Rockestate, un nouveau site Web pour aider ses utilisateurs à estimer le prix d'une maison. Rockestate a construit le modèle derrière les estimations. Cet article explique les bases de ce modèle prédictif.
Remarque: avant de plonger dans ce blog, nous vous suggérons d’essayer l’Indicateur de Prix de Zimmo.
Comme nous le savons tous, l’emplacement et les caractéristiques d’une maison déterminent son prix. Une grande villa coûte généralement plus cher qu’une petite maison et une maison située dans le centre-ville de Bruxelles vaut souvent plus qu’une maison à la campagne. La construction d’un modèle de régression qui exploite avec succès ces différentes relations pour estimer le prix d’une maison est un exemple classique dans de nombreux cours de science des données.
Zimmo, une plate-forme d’annonces immobilières en ligne, fait partie des pionnières en Belgique à présenter une estimation du prix d’une maison en fonction de ses caractéristiques. Cependant, que signifie exactement une telle estimation? La plupart des utilisateurs ont du mal à comprendre une prédiction de prix sans contexte et explications supplémentaires. En conséquence, ils n’y attachent que très peu d’importance.
Zimmo a développé, avec Rockestate, un nouvel outil, appelé “Indicateur de Prix” , qui va bien au-delà du simple calcul d’une estimation. Comme pour tout modèle prédictif, l’Indicateur de Prix tente de prévoir les prix de l’immobilier avec précision. Cependant, l’objectif principal est de fournir aux utilisateurs un outil leur permettant de déterminer ce qu’un prix correct est censé être en utilisant les données disponibles. Il existe des différences cruciales entre ces deux perspectives (précision vs. interprétation) que nous abordons plus en détail dans cet article.
Lorsque nous jetons un coup d’oeil derrière le rideau, nous trouvons un modèle de régression comme étant le moteur derrière les estimations. Nous avons choisi de mettre en œuvre un modèle de régression particulier appelé Régression Géographiquement Pondérée (RGP). Nous expliquons comment cela fonctionne et pourquoi nous croyons que ce modèle en particulier aide les utilisateurs à mieux estimer le prix.
Annonces immobilières en ligne servant comme source de données
Notre source d’informations principale est la liste des annonces immobilières sur Zimmo. En Belgique, il y a environ 100.000 transactions immobilières chaque année. Comme la plupart des propriétés mises en vente disposent d’une annonce en ligne, de nombreuses données sont disponibles. Cependant, toute information n’est pas forcément utile. Il existe plusieurs raisons pour lesquelles les annonces en ligne ne sont pas toujours fiables ou immédiatement utilisables dans une approche pilotée par les données:
- L’annonce ne contient pas d’adresse. Les agents immobiliers ont tendance à cacher l’adresse pour s’assurer que l’acheteur potentiel ne visite pas la propriété sans avoir au préalable contacté l’agent.
- L’annonce n’a pas beaucoup de caractéristiques du bien. L’utilisateur n’a peut-être pas pris la peine de les remplir, ou les informations demandées étaient inconnues (ceci mène à beaucoup de valeurs manquantes).
- L’annonce n’a pas résulté en une vente réelle; ou bien cela a conduit à une transaction à un prix différent de celui affiché. Cela indique un décalage entre le prix demandé et les caractéristiques de la propriété.
En tant que plate-forme immobilière en ligne, Zimmo s’efforce de rendre ses données aussi précises que possible. (La qualité des données compte, et nous avons adoré travailler avec les sources de données bien gérées de Zimmo!) Grâce à cette base de données d’annonces immo, nous pouvons ensuite rechercher des corrélations entre les propriétés de la maison et le prix. Comme vous le remarquerez dans l’image ci-dessous de nombreuses propriétés de l’habitation sont fortement corrélées avec le prix. Avec un modèle statistique, nous essayons d’exploiter précisément ces relations afin de prévoir le prix.

L’inconvénient de l’utilisation des annonces immobilières est que nous modélisons le prix affiché et non le réel prix de transaction. Grâce au travail que nous effectuons pour les banques, nous avons pu utiliser les données des prêts hypothécaires pour démontrer que le prix demandé est fortement corrélé au prix de transaction. En moyenne, les prix affichés se révèlent légèrement plus élevés par rapport au prix de transaction réel. Cela correspond tout à fait à ce à quoi on pourrait s’attendre.
Un autre inconvénient est que les annonces contiennent des informations subjectives. Un bon exemple est l’état de la maison. La plupart des gens qui vendent une maison ont tendance à croire que leur maison est dans un état plutôt bon alors que l’acheteur potentiel peut être de l’avis qu’elle a besoin d’une rénovation (sérieuse). Nous n’utilisons donc que des critères laissant peu de place à l’interprétation, tels que la surface du terrain, la surface habitable, le nombre de chambres à coucher, l’efficacité énergétique (certificat PEB) et l’année de construction. Cela illustre en quoi notre modèle diffère de la plupart des autres. L’inclusion de paramètres subjectifs peut conduire à des prévisions plus précises, mais cela crée également une incertitude supplémentaire, car l’utilisateur doit d’abord estimer la valeur subjective de la caractéristique respective. Souvent, cela n’améliore pas l’expérience globale de l’utilisateur.
Régression Géographiquement Pondérée (RGP)
Nous avons implémenté une version d’une régression géographiquement pondérée (“Geographically Weighted Regression”) pour prédire le prix d’une maison. Comme son nom l’indique, RGP est une régression linéaire qui prend en compte les informations spatiales et attribue une pondération plus élevée aux maisons avoisinantes lors de l’estimation du prix d’une maison. L’image ci-dessous illustre le schéma de pondération d’une maison aléatoire. Plus le point est élevé, plus la maison avoisinante reçoit de poids.

Nous sommes en 2019, pourquoi utiliser une régression linéaire?
Bien que la science des données fasse actuellement l’objet de beaucoup de développements innovants comme les modèles “black box” et le “machine learning”, nous optons néanmoins pour un modèle statistique relativement simple. Comme nous l’avons expliqué précédemment, l’accent est mis sur l’interprétabilité. En outre, la plupart de nos caractéristiques de maison objectives ont une relation monotone croissante ou décroissante avec la maison, par exemple:
- Une maison avec un grand jardin coûte en moyenne plus cher par rapport à une maison avec un petit jardin.
- Une maison de 4 chambres est en moyenne plus chère qu’une maison de 3 chambres.
- Une maison avec une faible PEB est en moyenne plus chère qu’une maison avec une PEB élevée.
Il existe de nombreuses façons de modéliser ces corrélations. Nous choisissons un modèle linéaire, car il suffit de quelques paramètres pour modéliser une relation linéaire. On peut bien sûr modéliser la relation avec un modèle plus compliqué, mais cela nécessite beaucoup plus d’observations pour atteindre le même pouvoir de prédiction.
(Il est intéressant de noter que certaines méthodes modernes d’interprétabilité font recours à des modèles à “boîte blanche” pour expliquer des modèles plus complexes, qui incluent parfois un facteur de pondération similaire à celui de RGP. Un example connu est la technique LIME)

Comment avons-nous modélisé la valeur de l’emplacement?
La valeur de la localisation est intrinsèquement incluse dans chaque estimation, car les prévisions sont basées sur un modèle contenant seulement des maisons avoisinantes, pondérées en fonction de leurs distances respectives. Au lieu d’inclure explicitement de nombreuses caractéristiques basées sur la localisation (par exemple, la distance au centre-ville, autoroute,…) dans la matrice des caractéristiques, nous n’incluons aucun paramètre basé sur la localisation, y compris la latitude ou la longitude. La valeur de l’emplacement est plutôt prise en compte en construisant un modèle de régression utilisant uniquement les annonces immobilières à proximité.
Il y a cependant un inconvénient: dans ce contexte, un modèle de régression doit être construit et mis au point “on the fly” pour chaque habitation à estimer. En pratique, il ne s’agit que d’un problème mineur, grâce à la puissance de calcul actuelle, au cloud computing et à la possibilité de précalculer des modèles sur une grille d’emplacements.
Une autre question concerne le nombre de biens (avec une annonce) à incorporer dans le modèle RGP (autrement dit, quelle devrait être la configuration des poids pour les maisons avoisinantes?). Cet hyperparamètre présente un exemple typique de compromis entre le biais et la variance:
- Si nous sélectionnons trop de maisons proches à inclure, la relation de localisation spécifique entre les caractéristiques et la maison est perdue.
- Si nous sélectionnons trop peu de maisons à proximité, il y a trop de bruit dans les données, de sorte que les corrélations ne sont pas correctement modélisées.
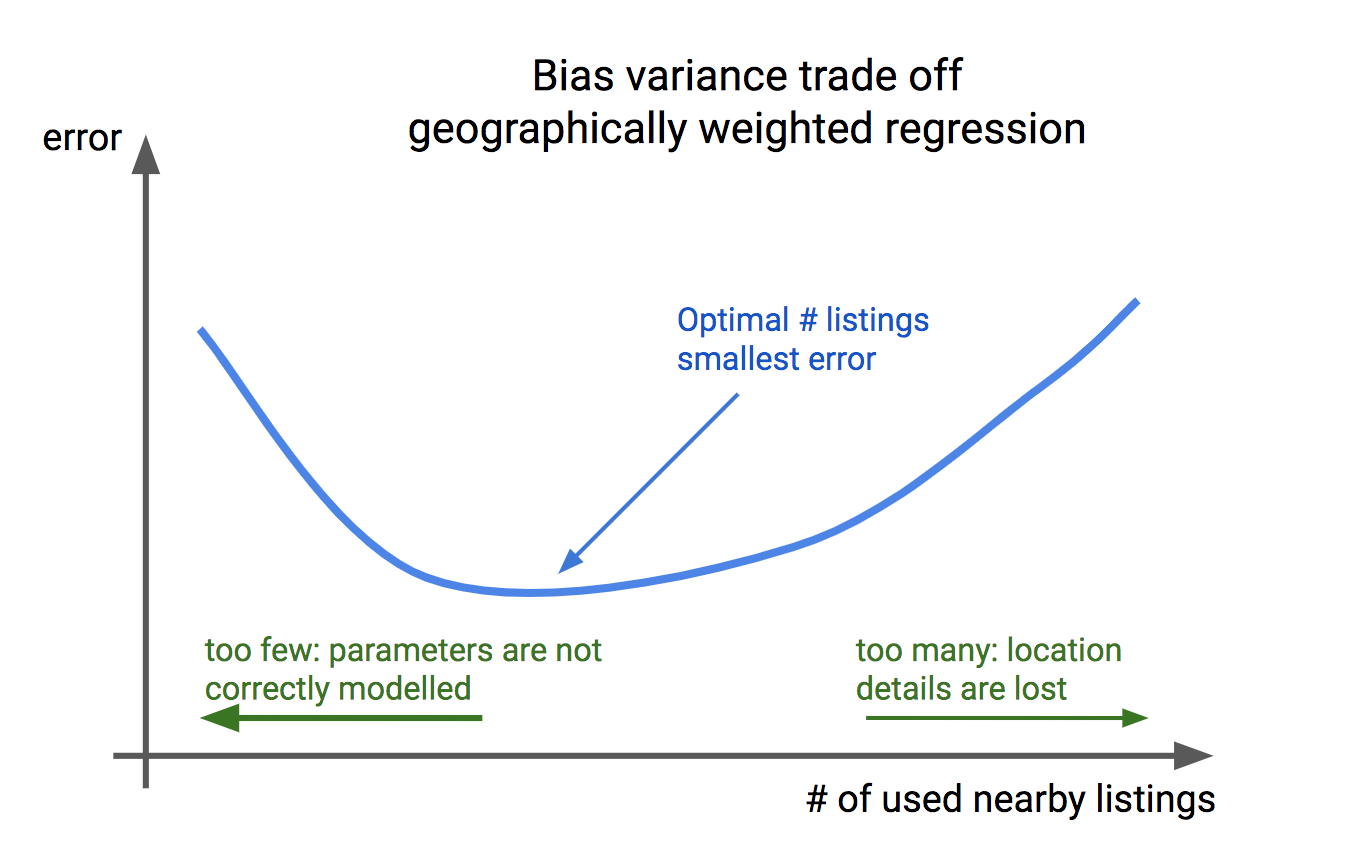
Ce paramètre doit être ajusté avec soin. Dans la pratique, nous trouvons que les détails et les aspects de localisation “à grande échelle” sont bien modélisés, tels que la qualité du voisinage général ou l’accessibilité d’une zone particulière. Les détails de petite taille, plus granulaires, tels que la vue d’une maison ou la pollution sonore ne sont malheureusement pas pris en compte.
Est-ce que ça marche bien?
La qualité du modèle comporte deux éléments essentiels. Le premier concerne l’expérience utilisateur de l’outil Indicateur de Prix. Grâce à un modèle simple et facile à interpréter, les utilisateurs peuvent désormais comprendre comment les prédictions sont construites et même ajuster les entrées pour voir comment le modèle réagit.
Le deuxième aspect concernant la qualité du modèle a trait à la précision statistique (c’est-à-dire dans quelle mesure le modèle est-il correct?). Nous avons constaté que le pouvoir prédictif de notre modèle est comparable à un modèle plus complexe tel que XGBoost. Notez que la puissance prédictive serait plus élevée aussi bien pour les modèles GWR que XGBoost lorsqu’un ensemble de paramètres plus étendu serait pris en compte. Nous avons toutefois choisi, pour diverses raisons exposées ci-dessus, de limiter le modèle à un ensemble limité de caractéristiques objectives.
N’hésitez pas à essayer l’Indicateur de Prix. Nous sommes intéressés d’avoir votre avis et nous vous souhaitons le meilleur pour le futur achat ou vente de votre maison.
Cet article de blog est une traduction de l’article original, écrit en Anglais.