Hoe helpt de Zimmo Prijswijzer bij het schatten van een woningprijs?
Zimmo heeft in samenwerking met Rockestate een nieuwe website gelanceerd om gebruikers te helpen bij het schatten van een woningprijs. Rockestate bouwde het onderliggende schattingsmodel. Deze blogpost legt de basis uit van dit voorspellende model.
Opmerking: voordat je deze blogpost leest, raden we je aan om de Zimmo Prijswijzer uit te proberen.
Zoals we allemaal weten, bepalen vooral de locatie en kenmerken van een woning de prijs. Een grote villa is meestal duurder dan een bescheiden rijwoning, en een huis in het centrum van Brussel is doorgaans meer waard in vergelijking met een huis op het platteland. Het bouwen van een regressiemodel om de prijs van een huis te schatten, door deze verbanden succesvol te exploiteren, is een schoolvoorbeeld in veel cursussen datawetenschappen.
Zimmo, een online vastgoedplatform, was een van de pioniers in België om een prijsraming van een huis te tonen op basis van zijn kenmerken. Wat kan zo’n schatting ons echter precies vertellen? De meeste gebruikers hebben moeite om een dergelijke prijsvoorspelling te begrijpen zonder aanvullende inzichten en uitleg. Daarom hechten ze er dikwijls weinig belang aan.
Zimmo ontwikkelde samen met Rockestate een nieuwe oplossing, de Prijswijzer, die veel verder gaat dan alleen het berekenen van een schatting. Zoals voor elk voorspellend model, probeert de Prijswijzer huizenprijzen nauwkeurig te voorspellen. Het belangrijkste doel is echter gebruikers een oplossing te bieden waarmee ze kunnen bepalen wat een correcte prijs hoort te zijn door de vele beschikbare gegevens te gebruiken. Er zijn enkele cruciale verschillen tussen deze twee perspectieven (precisie vs. interpretatie) die we verderop in deze blogpost bespreken.
Wanneer we een kijkje nemen onder de motorkap, vinden we een regressiemodel die de schattingen aanstuurt. We opteerden voor de implementatie van een welbepaald regressiemodel, genaamd Geografisch Gewogen Regressie (GWR). We leggen uit hoe het werkt en waarom we geloven dat dit specifieke model gebruikers helpt om de prijs zelf beter te schatten.
Online vastgoedadvertenties als gegevensbron
Onze voornaamste informatiebron is gebaseerd op de Zimmo-advertenties. In België zijn er elk jaar ongeveer 100.000 vastgoedtransacties. Aangezien de meeste te koop staande woningen ook een online advertentie hebben, zijn er heel wat gegevens beschikbaar. Niet alles is echter nuttig. Er zijn tal van redenen waarom online zoekertjes niet altijd betrouwbaar zijn of onmiddellijk geschikt zijn voor gebruik in een data-gestuurde aanpak:
- De advertentie heeft geen adres. Makelaars hebben soms de neiging om het adres te verbergen zodat de potentiële koper het pand niet zou bezoeken zonder eerst contact op te nemen met de makelaar.
- Er zijn weinig pandeigenschappen ingevuld in het zoekertje. De gebruiker heeft mogelijk niet de moeite genomen om deze in te vullen, of de gevraagde informatie was onbekend (hetgeen leidt tot veel ontbrekende waarden).
- De aanbieding heeft niet geleid tot een daadwerkelijke verkoop; of het leidde tot een transactie aan een andere prijs dan die was geadverteerd. Dit wijst op een mismatch tussen de vraagprijs en de kenmerken van de woning.
Als online vastgoedplatform werkt Zimmo hard om ervoor te zorgen dat de advertentiegegevens in haar database zo nauwkeurig mogelijk zijn. (Datakwaliteit is belangrijk en we werkten graag met de goed onderhouden databronnen van Zimmo!) Met deze database van zoekertjes zoeken we vervolgens naar correlaties tussen de eigenschappen van de woning en de prijs. De onderstaande afbeelding illustreert dat vele eigenschappen van een huis sterk gecorreleerd zijn met de prijs. Met een statistisch model proberen we precies deze relaties te benutten om de prijs te voorspellen.

Een nadeel van het gebruik van online vastgoedzoekertjes is dat we de vraagprijs voorspellen en niet de transactieprijs. Dankzij het werk dat we doen voor banken, hebben we echter gegevens van hypothecaire leningen kunnen gebruiken om te bewijzen dat de vraagprijs sterk gecorreleerd is met de transactieprijs. Gemiddeld gezien ligt de vraagprijs iets hoger dan de werkelijke transactieprijs. Deze vaststelling ligt geheel in lijn van wat men zou verwachten.
Een ander nadeel is dat online advertenties heel wat subjectieve informatie bevatten. Een goed voorbeeld is de staat van een woning. De meeste mensen die een huis verkopen, zijn dikwijls van mening dat deze in een redelijk goede staat is, terwijl de potentiële koper eerder vindt dat het een (serieuze) renovatie nodig heeft. We gebruiken daarom alleen criteria die weinig ruimte laten voor interpretatie zoals perceel- & bewoonbare oppervlakte, aantal slaapkamers, energie-efficiëntie (EPC) en het bouwjaar. Dit illustreert hoe ons model verschilt van de meeste anderen. Het gebruiken van subjectieve parameters kan eventueel bijdragen tot accuratere voorspellingen, maar het creëert ook extra onzekerheid omdat de gebruiker eerst de subjectieve waarde van de in te geven woningeingenschappen moet schatten. Dit draagt niet bij tot een verbetering van de algemene gebruikerservaring.
Geografisch Gewogen Regressie (GWR)
We gebruiken een versie van een geografisch gewogen regressie (“Geographically Weighted Regression”) om de woningprijs te voorspellen. Zoals de naam aangeeft betreft het een lineaire regressie die rekening houdt met ruimtelijke informatie en hogere gewichten geeft aan nabijgelegen woningen bij het schatten van de woningprijs. De onderstaande afbeelding illustreert de gewichtsverdeling voor een willekeurig huis. Hoe hoger de stip, hoe meer gewicht het nabijgelegen huis krijgt.

Het is 2019, waarom lineaire regressie?
Hoewel de datawetenschappen zich momenteel in een ware hype bevinden met ontwikkelingen rond “black box”-modellen of “deep learning”, kiezen we er bewust voor om een relatief eenvoudig, statistisch, “white box”-model te gebruiken. Een belangrijke reden om dit te doen is onze focus op interpreteerbaarheid, zoals we eerder hebben uitgelegd. Bovendien hebben de meeste van de door ons gedefinieerde objectieve woningkenmerken een monotoon toenemende of afnemende relatie met de woning, zoals bijvoorbeeld:
- Een huis met een grote tuin is gemiddeld duurder in vergelijking met een huis met een kleine tuin.
- Een huis met 4 slaapkamers is gemiddeld duurder in vergelijking met een huis met 3 slaapkamers.
- Een huis met een lage EPC-waarde is gemiddeld duurder in vergelijking met een huis met een hoge EPC-waarde.
Er zijn talloze manieren om deze correlaties te modelleren. We kiezen een lineair model omdat er slechts enkele parameters nodig zijn om een lineair verband te modelleren. Je kunt natuurlijk deze relaties ook met een meer gecompliceerd model modelleren, maar je hebt in dat geval veel meer observaties nodig om dezelfde voorspellingskracht te bereiken.
(Als kanttekening is het interessant om erop te wijzen dat sommige moderne interpretatiemethoden ook gebruik maken van “white box”-modellen om complexere modellen uit te leggen. Sommigen bevatten zelfs een gewicht component vergelijkbaar met GWR, zoals bijvoorbeeld de bekende LIME techniek.)

Hoe hebben we de waarde van de locatie gemodelleerd?
De waarde van de locatie is intrinsiek opgenomen in elke voorspelling, omdat de voorspellingen gebaseerd zijn op een model gevoed met alleen nabijgelegen woningen, gewogen op basis van hun respectievelijke afstand. In plaats van het expliciet integreren van verschillende locatie-gerelateerde kenmerken (bijvoorbeeld afstand tot school, stadscentrum, snelweg, …) in de functiematrix nemen we geen enkele locatieparameter in beschouwing, inclusief breedte- of lengtegraden. In plaats daarvan wordt rekening gehouden met de waarde van de locatie door een regressiemodel te maken met alleen data van andere zoekertjes in de buurt.
Er is echter een keerzijde: in deze opzet moet een regressiemodel “on the fly” worden gebouwd en getraind voor elke locatie die men wil voorspellen. In de praktijk vormt dit slechts een beperkte uitdaging dankzij de huidige rekenkracht, cloud computing en de mogelijkheid om modellen vooraf te berekenen over een raster van locaties.
Een andere vraag betreft het aantal panden (met zoekertjes) dat in het GWR-model moet worden opgenomen (met andere woorden, de configuratie van de gewichten over de nabijgelegen huizen). Deze hyperparameter is een typisch voorbeeld van een afweging tussen bias en variantie:
- Als we te veel woningen in de buurt selecteren, gaat de locatiespecifieke relatie tussen kenmerken en het huis verloren.
- Als we te weinig huizen in de buurt selecteren, is er te veel ruis in de gegevens waardoor de correlaties niet correct worden gemodelleerd.
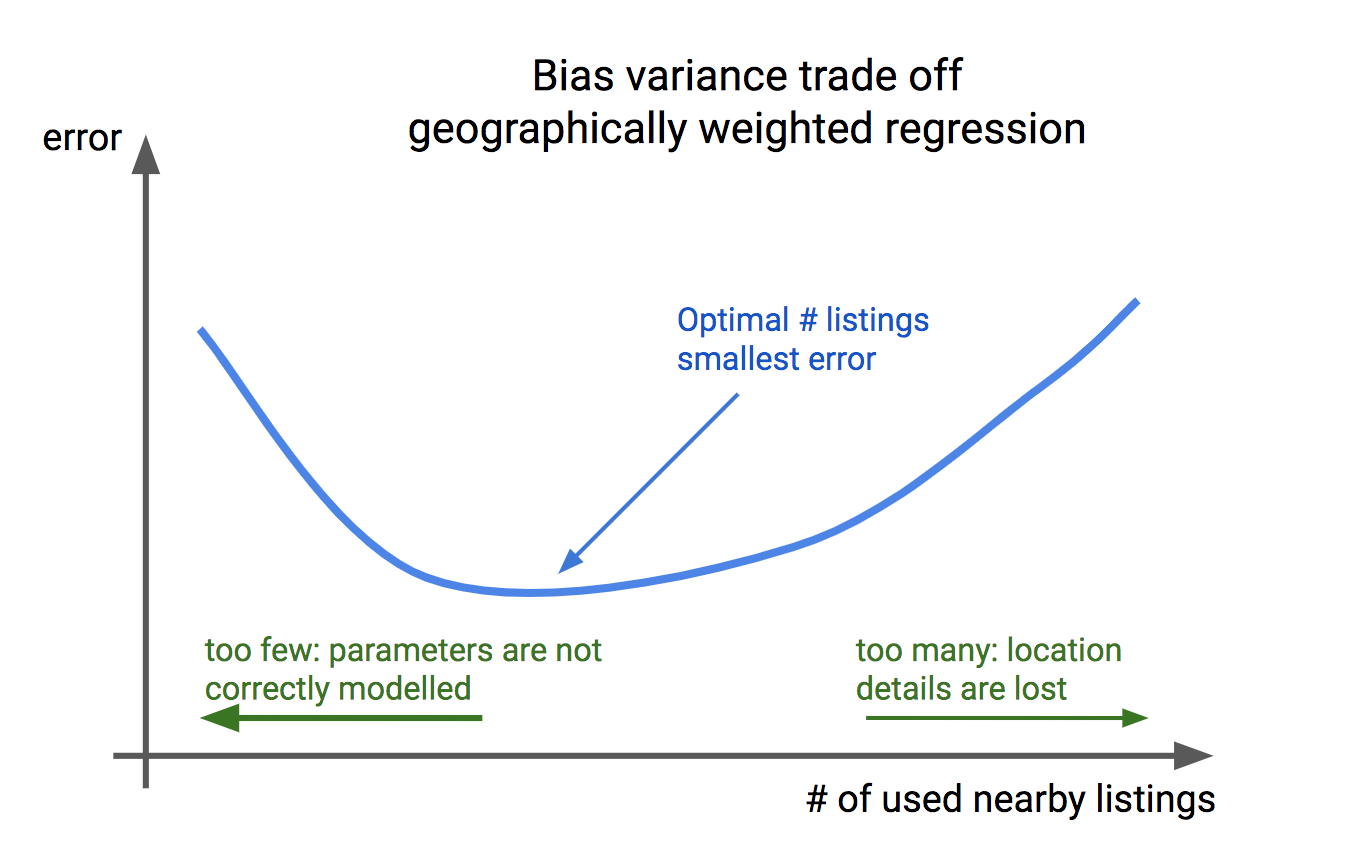
Deze parameter moet dusdanig zorgvuldig worden ingesteld. In de praktijk zien we dat “grootschalige” locatiegegevens en -eigenschappen goed worden gemodelleerd, zoals de kwaliteit van de algemene buurt of de bereikbaarheid van een bepaald gebied. Kleinschalige locatiegegevens zoals uitzicht op de tuin of geluidsoverlast worden helaas niet in aanmerking genomen.
Hoe goed werkt het?
De kwaliteit van het model heeft twee essentiële elementen. De eerste heeft betrekking op de gebruikerservaring van de Prijswijzer-tool. Dankzij een eenvoudig, gemakkelijk te interpreteren, model kunnen gebruikers voortaan begrijpen hoe voorspellingen worden opgebouwd. Ze kunnen ze zelfs de inputparameters aanpassen om te zien hoe het model reageert.
Het tweede luik van de model kwaliteit heeft betrekking tot de statistische nauwkeurigheid (d.w.z. hoe correct is het model?). We hebben geconstateerd dat de voorspellende kracht van ons model vergelijkbaar is met een meer gecompliceerd model zoals XGBoost. We wensen op te merken dat het voorspellende vermogen hoger zou zijn voor zowel de GWR- als de WGBoost-modellen indien een meer uitgebreide reeks aan parameters zou worden gebruikt. We hebben er echter om verschillende redenen voor gekozen om het model te beperken tot een beperkt aantal objectieve kenmerken.
Probeer de Zimmo Prijswijzer zelf uit. We zijn benieuwd naar uw ervaringen en we wensen u alvast veel succes bij het kopen of verkopen van uw woning.
Deze blogpost is een vertaling van de originele blogpost in het Engels.