How does the Zimmo Prijswijzer help to estimate the price of a house?
Zimmo has launched, in collaboration with Rockestate, a new website to help its users to estimate the price of a house. Rockestate has built the model behind the website. This blog post explains the basics of this predictive model.
Note 1: a translation of this blog post is available in Dutch or in French.
Note 2: before diving into this blog post, we suggest you try out the Zimmo Prijswijzer.
As we all know, the location and characteristics of a house determine its price. A large villa is usually more expensive than a small house, and a house in the city center of Brussels is often worth more compared to a house in the countryside. Building a regression model that successfully exploits these relationships to estimate the price of a house is a textbook example in many data science courses.
Zimmo, an online real estate platform, was one of the pioneers in Belgium to show a price estimation of a house based on its characteristics. However, what can such an estimation tell us exactly? Most users have difficulties understanding such a price prediction without additional insights and explanations. As a result, they attach very little importance to it.
Zimmo developed, together with Rockestate, a new tool, called the Prijswijzer (roughly translated as “Price Counselor”), which goes well beyond calculating just an estimation. As for any predictive model, the Prijswijzer tries to predict house prices accurately. However, the main goal is to provide users with a solution that allows them to determine what a correct price is supposed to be by using the available data that is out there. There are some crucial differences between these two perspectives (precision vs. interpretation) which we touch upon further in this blog post.
When we take a peek behind the curtain, we can find a regression model as being the driver behind the estimates. We chose to implement a particular regression model called Geographically Weighted Regression (GWR). We explain how it works and why we believe this particular model helps users to estimate the price themselves better.
Online listings as a data source
Our primary source of information is Zimmo ad listings. In Belgium, there are around 100.000 real estate transactions every year. Since most properties put for sale have an online ad listing, there is a lot of data available. However, not all of it is useful. There are many reasons why online listings are not always reliable or immediately fit for use in a data-driven approach:
- The listing doesn’t have an address. Real estate agents tend to hide the address to make sure the potential buyer does not visit the property without first contacting the agent.
- The listing doesn’t have many characteristics filled in. The user possibly didn’t bother to fill these in, or the requested information was unknown (i.e. this leads to lots of missing values).
- The listing did not lead to an actual sale; or it led to a transaction at a different price from what had been listed. This indicates a mismatch between the listing price and the characteristics of the property.
As a real estate online platform, Zimmo works hard to make sure the listing data in its database is as accurate as possible. (Data quality matters, and we loved working with Zimmo’s well-maintained data sources!) With this database of online listings, we can then look for correlations between the properties of the house and the price. As you notice in the image below, many properties of the house are highly correlated with the price. With a statistical model, we try to exploit precisely these relationships to predict the price.

A downside of using online listings is that we are modeling the listing price and not the transaction price. Thanks to the work we do for banks, we have been able to use mortgage loan data to prove that the listing price is highly correlated with the transaction price. On average, asking prices turn out to be slightly higher compared to the actual transaction price. This is very much in line with what one would expect.
Another downside is that online listings contain subjective information. A great example is the condition of the house. Most people who sell a house tend to believe their house is in a rather good state while the potential buyer may argue it needs some (serious) renovation. We therefore only use criteria that leave little room for interpretation such as parcel/living area, number of bedrooms, energy efficiency (EPC/PEB), and the construction year. This illustrates how our model differs from most others. Including subjective parameters can lead to more accurate predictions but it also creates additional uncertainty since the user first has to estimate the subjective value of the input characteristic. More often than not, this does not improve the overall user experience.
Geographically Weighted Regression (GWR)
We have implemented a version of a geographically weighted regression to predict the price of a house. As the name says, GWR is a linear regression that takes spatial information into account and gives higher weights to nearby houses when estimating the price of a house. The image below illustrates the weighting scheme for a random house. The higher the dot, the more weight the nearby house receives.

It’s 2019, why use linear regression?
Although data science is currently undergoing a hype around black box models or “deep learning”, we still opt to employ a relatively simple, statistical, white-box model. One important reason to do so is our focus on interpretability, as we explained previously. Also, most of our curated set of objective house characteristics have a monotonically increasing/decreasing relationship with the house, e.g.:
- A house with a large garden is on average more expensive compared to a house with a small garden.
- A house with 4 bedrooms is on average more expensive compared to a house with 3 bedrooms.
- A house with a low EPC is on average more expensive compared to a house with a high EPC.
There are numerous ways of modeling these correlations. We choose a linear model as one needs only a couple of parameters to model a linear relationship. You can, of course, model the relationship with a more complicated model, but you need a lot more observations to reach the same prediction power.
(As a side note it is interesting to point out that some modern interpretability methods also resort to using white-box models to help explain more complex ones. These sometimes even include a weight component similar to GWR, which can be found in the well known LIME technique.)

How did we model the value of the location?
The value of the location is intrinsically included in a prediction, as the predictions are based on a model with only nearby houses, weighted based on distance. Instead of explicitly including many location-based characteristics (e.g. distance to school, city center, highway, …) in the feature matrix, we do not include a single location-based parameter, including latitude or longitudes. Instead, the value of the location is taken into account by building a regression model using only nearby listings.
There is one downside however: in this setting, a regression model needs to be constructed and trained “on the fly” for every location one wants to predict. In practice, this is only a minor issue thanks to the current computational power, cloud computing, and the possibility to precompute models over a grid of locations.
Another question entails the number of properties (listings) to incorporate in the GWR model (in other words, the configuration of the weights over the nearby houses). This hyperparameter entails a typical example of a bias-variance tradeoff:
- If we select too many nearby houses to include, the location-specific relationship between characteristics and the house is lost.
- If we select too few nearby houses, there is too much noise in the data so that the correlations are not modeled correctly.
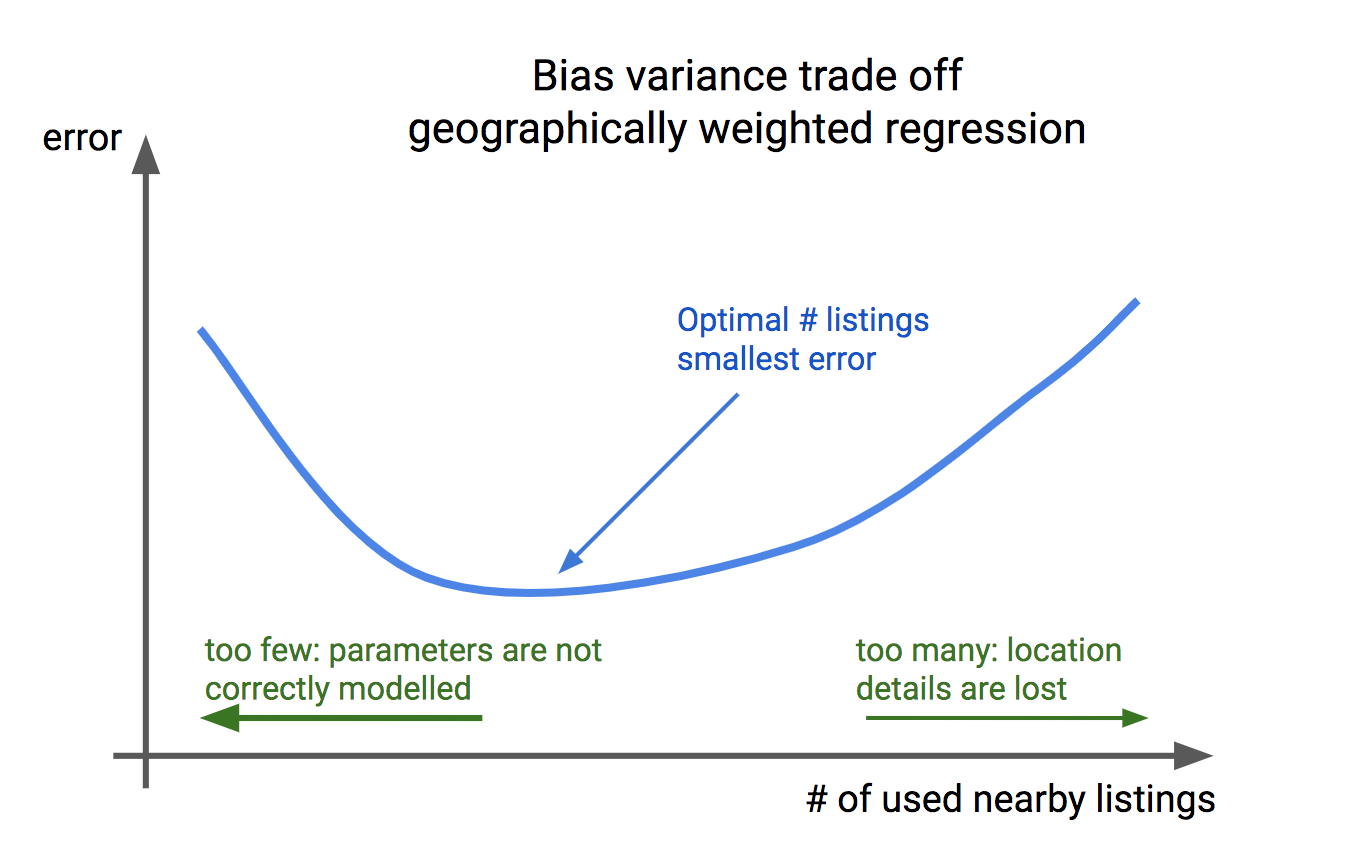
This parameter needs to be carefully tuned. In practice, we find that “large scale” location details and aspects are well modeled, such as the quality of the general neighborhood or the accessibility of a particular area. Small scale, granular, location details such as a garden view or noise pollution are unfortunately not taken into account.
How well does it work?
The quality of the model has two essential elements. The first one relates to the user experience of the Prijswijzer tool. Thanks to a simple, easy-to-interpret, model, users can now understand how predictions are constructed and can even tweak the inputs to see how the model reacts.
The second aspect regarding model quality relates to statistical accuracy (i.e. how correct is the model?). We have found that the predictive power of our model is comparable to a more complicated model such as XGBoost. Note that the predictive power would be higher for both the GWR and the XGBoost models when a more extensive feature set would be considered. We have chosen though, for various reasons stated above, to restrict the model to a limited set of objective characteristics.
Feel free to try out the Zimmo Prijswijzer for yourself. We’re eager to hear about your experience, and we wish you all the best selling or buying your house.